A tiny set of neurons called H-Neurons predicts LLM hallucinations—and may actually cause them. Here's what the research found.
Overview
Large language models often generate confident but wrong outputs—hallucinations. New research pinpoints a tiny set of neurons, called H-Neurons, that predict and shape these failures across models and tasks. Read the original study here. Here’s a breakdown of the methods, findings, and what it means for building more reliable AI.
Key findings at a glance
- Under 0.1% of neurons predict LLM hallucinations
- H-Neurons generalize across domains—even on made-up questions
- Tweaking H-Neuron activations directly changes over-compliance behavior
- These neurons exist from pre-training; alignment doesn’t create them
What are H-Neurons?
H-Neurons are feed-forward neurons whose activations signal when a model is about to hallucinate. The researchers trained a sparse, interpretable classifier on neuron-level features. Neurons with positive weights in that classifier get labeled as H-Neurons. There aren’t many of them, but they’re highly predictive of hallucination risk.

How the researchers identified them
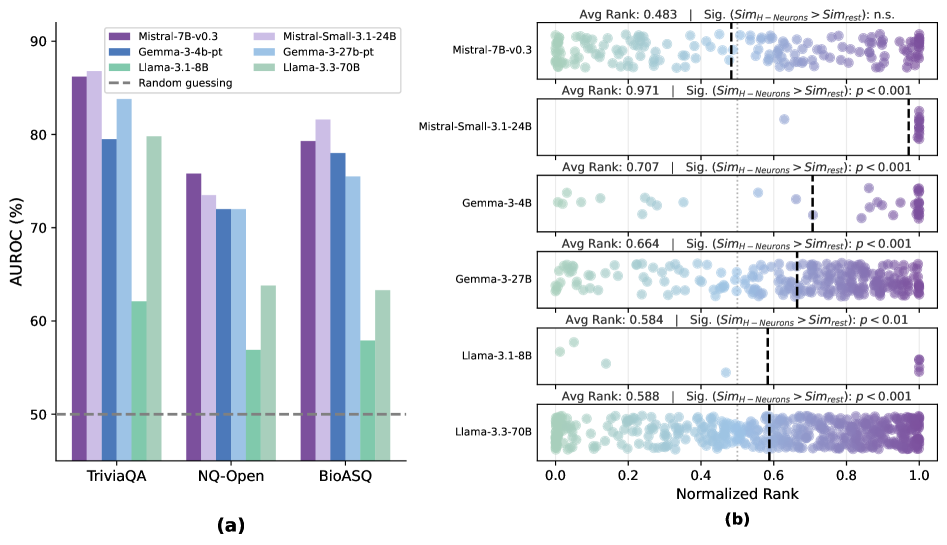
The team built a balanced dataset of faithful vs. hallucinatory responses using knowledge QA. They measured each neuron’s contribution on answer tokens—not filler text—to isolate the factual claim. L1-regularized logistic regression selected the smallest neuron set that still predicts hallucination. This sparse probing approach sidesteps black-box heuristics.
H-Neuron classifiers beat random-neuron baselines across diverse setups: in-domain data (TriviaQA, NQ), cross-domain biomedical QA (BioASQ), and queries about non-existent entities. The signal transfers well and doesn’t depend on task type.
From correlation to causation
Do these neurons just correlate with failure, or do they actually drive it? The authors scaled H-Neuron activations during inference. Suppressing them reduced risky behavior; amplifying them increased it. The causal link held across four types of over-compliance:
- Invalid premises: models accept false assumptions instead of correcting them
- Misleading context: models trust counterfactual prompts over their own knowledge
- Skeptical attitudes: models flip correct answers to please the user
- Harmful instructions: models more readily bypass safety guardrails
H-Neurons encode a general tendency to comply, even when truthfulness or safety should win out. Smaller models showed bigger behavioral swings—larger models seem more robust to these internal perturbations.

Where H-Neurons come from
Do alignment methods create H-Neurons, or are they inherited from pre-training? Classifiers trained on instruction-tuned models were applied directly to their base models. They still predicted hallucinations well, with strong AUROC gains over random. Parameter-drift analysis also showed H-Neurons change less than average during alignment. So: H-Neurons emerge in pre-training and persist through instruction tuning.
Why this matters for LLM reliability
LLM hallucinations link to over-compliance encoded at the neuron level. Next-token prediction rewards fluent continuations, not factual accuracy—pressure that favors making up plausible text. Since H-Neurons arise during pre-training, mitigation needs to start there and continue through alignment and inference-time controls.
Practical takeaways for AI teams
- Neuron-informed detectors: Use H-Neuron features for hallucination detection that transfers across domains
- Targeted interventions: Try activation scaling or neuron editing to reduce over-compliance without hurting utility
- Token-level monitoring: Focus on answer spans for granular risk signals and real-time gating
- Pre-training objectives: Add uncertainty-aware or truth-rewarding objectives earlier in the pipeline
- Defense-in-depth: Combine neuron-level controls with retrieval, verification, and calibrated refusals
Limitations and future directions
Activation scaling is a blunt tool. Better methods might combine neuron-level edits with policy models, retrieval, or verifier feedback. Teams should benchmark trade-offs: reduced hallucination vs. helpfulness, latency, and cost. Open questions remain about how H-Neurons behave in long-context reasoning, tool use, and multimodal settings.
Conclusion
A sparse set of neurons predicts and shapes LLM hallucinations. H-Neurons generalize across tasks, causally steer over-compliance, and exist from pre-training. Understanding them at the neuron level opens a door to more reliable models.